本文共 2322 字,大约阅读时间需要 7 分钟。
快速复习
在前一篇文章中,“,”我写了关于算法学习分类。你会发现一些关于CRISP-DM方法的个人见解。
算法学习分类
当开始了KXEN的旅行时,并没有一个在数据挖掘或数据科学领域的谱系说明。我有技术支持和程序员的背景,因此,我理解了“算法”这个词在编程方面的含义,并且发现对于数据科学来说,也没有什么区别。

当还在学校的时候,我们就解决了代数问题,例如“找到通过两点(1,1)和(1, 2)之间直线的方程”或“找到函数f(x)=x4-8×2+5的最大值和最小值。
有很多算法可以帮助你去解决单一类型的问题,在机器学习项目中通常是由数据挖掘目标进行表示的。
所以,我们需要一种方法来组织算法的工具包。在这里,我将使用一种叫做“学习分类”的概念。
使用“学习分类”帮助你思考如何进行准备并使用你的数据来建立模型。最后,你会尝试选择最合适的算法来测试。
让我们来看看机器学习算法和相关的子类别的主要学习分类。
监督学习
使用监督学习,你将用一组标记过的数据来推导一个函数,其中结果(目标)是已知的。这个数据集也被称为训练数据集。
训练数据集可以被表示为由一个特征向量输入(或变量、维度)和相关联的输出值组成的数据对。
因此,监督学习算法的目标是分析训练数据,并产生一个函数,该函数可以对新的特征向量输入进行评分,并得到预测输出值。
这将要求算法从训练数据中对模式进行泛化(在推断函数中),以便以“合理”、正确的方式确定对任何新的和看不见的特征向量输入的输出值。
目前有大量的监督学习算法,它们各有各的的长处和短处。这意味着没有一个“全能”算法可以解决所有监督学习的问题。
你可以进一步对监督学习算法进行分组:
分类
这种方式适用于当目标被表示为一类的时候,如“真”和“假”或“A”和“B”的二元分类,或“A”,“B”,和“C”的一个多类别分类。
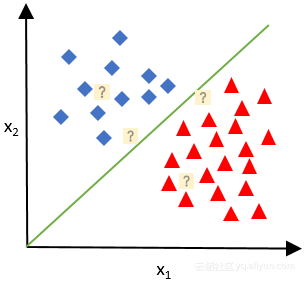
下图表描述了一个简单的分类示例,其中每个图标基于其输入值(x1和x2轴)进行定位,并基于输出值标记颜色。推断函数是绿线(这里是线性函数),每个问号是推断函数将被分配给一侧或另一个的新输入。
回归
这种方式适用于目标被表示为一个连续的数字的时候,比如财政收入、重量或温度时。
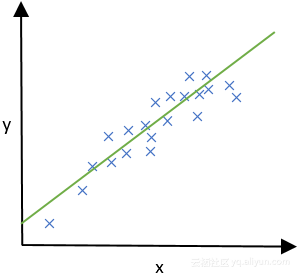
下图描述了一个简单的回归示例,其中每个标记基于其输入值(x轴)和输出值(y轴)来定位。推断函数是绿线,它可以为任何“X”输入值获得“Y”输出值。
时间序列预测
适用于当训练数据集表示一个信号或一系列的值时,在这里,你需要使用以前的数据来推断下一个N值。
有些人可能认为时间序列预测是一种回归,除了时间序列的推断函数将产生一系列的值,而不是在回归中的一个值。
另外,时间序列的数据集结构需要具有唯一值的“排序”列(通常是日期,但在某些情况下也可能是个增量列)
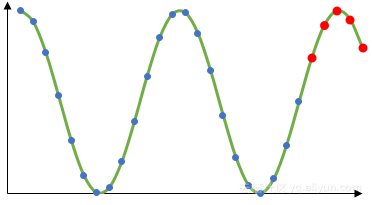
下面的例子显示了固定区间中的一系列点:标记为蓝色的点。时间序列算法推断函数(绿线)表示余弦函数,该余弦函数可用于预测后续5个值(红色的点)
综上所述,分类和回归的最大区别是目标变量(输出)的表达方式,其中一个是离散的(类别),而另一个是连续的。
无监督学习
与监督学习相反,使用无监督学习,你将使用一组未标记的数据(没有定义的结果)来推导出一个函数。
因此,推导函数是用来描述在数据中隐藏的底层结构和模式或分布。与监督学习不同,没有真正的方法来评估所找到的结构和模式的准确性或相关性。
你可以进一步对无监督学习算法进行分组:
聚类
这种类型的算法的适用情况是,当需要对比综合分布,而根据实体属性的“相似性”或“差别距离”来定义实体组(a.k.a.集群)时。每个聚类算法都有自己的分组策略,其基于距离中心的距离、组密度、组分布等,就像一些允许或防止重叠,或存在剩余项一样。
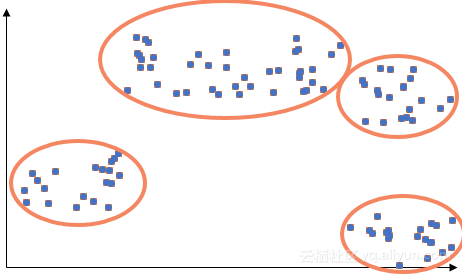
在下面的示例中,这个算法用到中心的距离定义了5个聚类。
关联规则
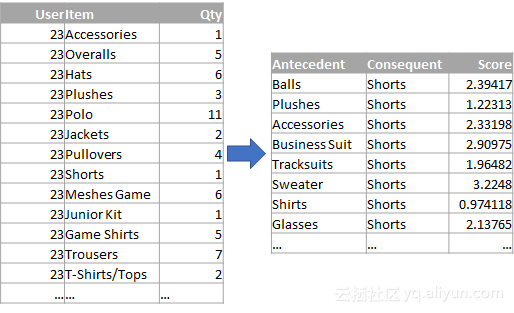
当使用事务性数据集将项目互相链接或将用户和项目链接时,可以应用这种类型的算法,而你的目标是提取有关关联的规则。一个常见的规则例子可以是当你购买Y时又买X。当然,规则可以在涉及多个项目或执行某个确定的序列的时间更长。
在下面的示例中,从一系列用户购物的交易中提取一组规则
其它的学习分类
半监督学习
在半监督学习中,只有一部分输入数据被标记了,这意味着算法必须通过结构学习来组织数据以及进行预测。
标记所有数据可能会变得费时费力,或者更糟的是,它们可能被错误地标记。
如果以一个图像库为例,只有一小部分图像将被标记。
因此,无监督学习和监督学习技术都被用来最好的利用未标记数据,将其与标记数据进行聚类或做出最佳的预测,并使用所有这些来构建模型。
增强学习
通过强化学习,该算法试图找到“最佳的方式”(一系列决策或行为)以获取最大的“回报”。
很典型的,在每一个步骤中,在导致一个回报和一个状态的环境中来做出决定。通过多次执行,该算法能够学习如何提高其决策能力和获得更大回报的能力。
参考
为了写这篇文章,我参考了一些有启发的、描述详细的和有想法的来源。
1.
2.
3.维基百科:
(1)
(2)
(3)
(4)
总结
希望这篇文章有助于清除机器学习中的一些术语,并帮助读者们理解这些算法,你可以使用自己的训练数据(标记或未标记的)创建最好的“函数”,然后就可以应用到新的数据集上了。
更新:下面的是每周在盒子博客上发表的所有的机器学习文章的链接:
·
·
·
·
·
·
·
·
以上为译文。
本文由北邮 老师推荐,组织翻译。
文章原标题《Machine Learning in a Box (week 3): Algorithm Learning Styles》,译者:Mags,审校:袁虎。
文章为简译,更为详细的内容,请查看。
转载地址:http://lslul.baihongyu.com/